Data Mesh ft. Google Cloud
Data and organizations’ data needs are growing exponentially, and up to 68% of companies struggle to realize measurable value from data. With a data mesh, businesses can implement democratic and agile data management practices, ultimately simplifying and improving how they maximize value from their data. Google’s Data Cloud provides businesses with a set of innovative tools and services to revolutionize data integration and analysis, to build better data meshes.
What is a Data Mesh?
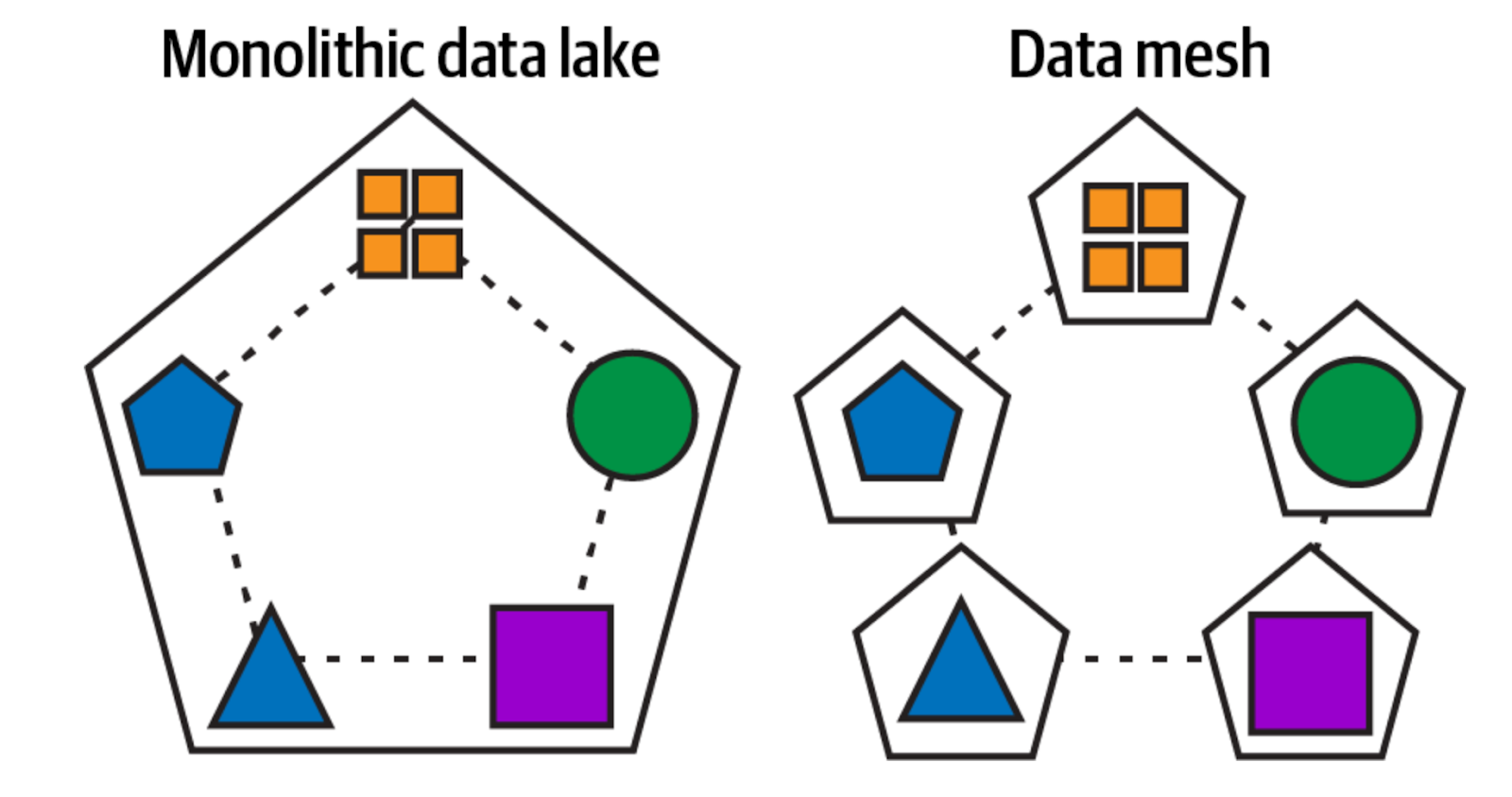
A data mesh is a decentralized approach to organizing and managing enterprise data. In this decentralized data architecture, data ownership and management in an organization is distributed across the teams that use it. We can see from the picture below that an approach called data lake encapsulates the whole organization’s data into one unit, while data mesh tries to divide that into smaller “meshes”. In this approach each mesh deals with their data and in between each other, they share only data products, which is the curated data that has business value already.
A data mesh mirrors a microservice architecture for app development. In fact, microservice is to app architecture what a data mesh is to data and analytics. They share similar principles to create autonomous and scalable systems.
Key principles of a data mesh
To build a self-sustaining distributed data architecture, a data mesh rests on the following principles:
Domain-oriented decentralized data ownership – Different business domains develop, deploy, and manage their own analytical and operational data services. For instance, sales and marketing departments are in charge of sales and leads data. This way, domains can curate their data to suit their needs better.
Data as a product – Each domain treats its data as a product. What this means is that, instead of raw data dumps, data is transformed into consumable and well-defined products. Let’s say a dataset is to be used to train AI models, it can undergo labeling, annotation, and feature engineering to be more informative to the model.
A self-serve data platform – The data mesh provides a central platform with standardized tools and resources that empower teams in the organization to access, test, and manage their data products. This reduces reliance on IT teams to do this for them.
Federated computational governance – While data ownership is decentralized, businesses should implement centralized governance of their data. Businesses should set well-defined standards for data quality, security, and access control consistently across the data mesh.
The benefits of a data mesh
Despite being a relatively new concept, more organizations are adopting a data mesh because of the following benefits:
High scalability and agility – As an organization’s data and data needs grow, the data mesh grows alongside.
Improved data accessibility – Users don’t have to go through the IT team to access data.
Enhanced data quality – Business domains treat their data as a product and optimize it for their use cases.
Better data governance – A data mesh leaves room for setting data standards to be applied across the organization.
Data mesh in the cloud
A data mesh perfectly aligns with cloud computing and, hence, is a great fit for enterprises looking to leverage the cloud for data management. First, the cloud provides resources on-demand to enable data meshes to easily handle growing data volumes.
In addition, cloud providers offer managed services like managed data warehouses, governance tools, and infrastructure provisioning that reduce the data management burden on individual business domains. On top of that, cloud storage facilitates easy data sharing and collaboration between domains. Data products can be easily accessed and integrated across the organization. Overall, cloud computing is a powerful enabler for data mesh architectures.
As one of the major cloud providers, Google Cloud has been utilizing data mesh principles to build data meshes internally. Fortunately, most of the tools it has been using to do this are now available for enterprises to use as part of Google’s Data Cloud.
Data Mesh in Google Cloud
In an ideal data mesh, every data user at a company:
Has timely access to the data and insights they need.
In the format they need it
Using tools that are familiar and comfortable to them.
Google Cloud is uniquely positioned to enable organizations to replicate a data mesh model closest to this with the services in its Data Cloud. These include BigQuery, Dataplex, Dataflow, and Dataprep.
BigQuery
BigQuery plays a crucial role in supporting a data mesh architecture on GCP. First, with BigQuery enterprises don’t need to centralize data engineering resources to provision and manage technical infrastructure for consumption. Being a managed service, BigQuery handles this for them so they can focus on more strategic tasks like building pipelines with Dataflow (more on this later).
BigQuery is both a storage and query engine making it an important part of the self-serve data platform of a data mesh. It integrates a powerful query engine that allows business domains to run complex queries on massive datasets using standard SQL (a familiar tool). In addition, its integration with Data Catalog makes this data easily discoverable. BigQuery also integrates with Cloud IAM to federate access to databases like Bigtable and Spanner.
Dataplex
Dataplex provides a single pane of glass for building independent data domains and maintaining central controls for governing data across domains. It allows organizations to logically organize data, code, policies, etc., in a data lake representing a data domain, for instance, sales.
Within the lake, you can refer to data in Cloud Storage buckets or BigQuery as Dataplex Assets and then group related assets as Dataplex Zones. For example, offline sales can be part of one zone.
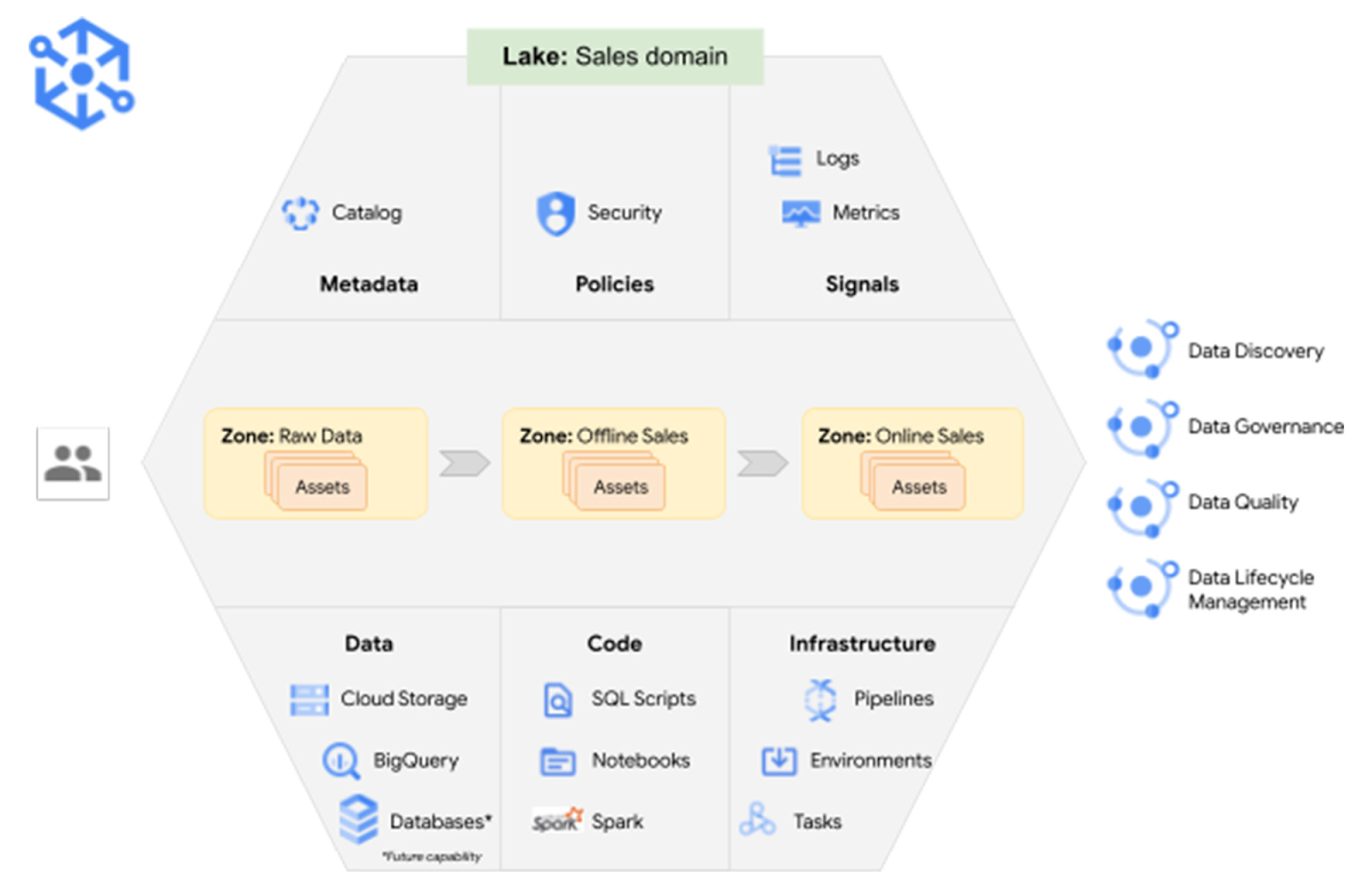
With Dataplex Lakes and Zones, you can unify distributed data and organize it depending on the business context. Then set governance policies, data quality monitoring, etc., to manage your distributed data from one place.
Integrations and tools
Dataplex’s integration with Data Catalog makes it easy to search, discover, and enrich domain data in data lakes. Access control to this data is governed by Cloud IAM. It allows businesses to scalably and consistently manage their IAM data policies to control access to distributed data. Dataplex also uses the Cloud Data Loss Prevention API, built-in data quality checks, and sensitive data tagging to tightly integrate data in the data mesh.
Dataflow and Dataprep
Dataflow
Dataflow enables business domains to transform raw data into valuable data products. With Dataflow, business domains can create their own data pipelines for data movement and processing.
Data can be cleaned, filtered, and enriched to meet the specific needs of the domain. Once data is transformed in the pipeline it can be forwarded to storage engines like BigQuery. Dataflow supports multiple programming languages like Java, Python, and Go, allowing domains to build pipelines using tools they’re comfortable with. Dataflow in the background is a managed Apache Beam solution.
Dataprep
Dataprep provides a user-friendly interface for visually exploring, cleaning, and transforming data. It forms a crucial part of the self-serve data platform, allowing non-technical users in a business domain to take ownership of data preparation tasks, using a simple drag and drop interface, with still powerful options
To sum up, Google’s Data Cloud equips enterprises with innovative tools, extremely useful within a data mesh workflow. In Google Cloud, enterprises can find everything they need to build an agile data ingestion, processing, storage, and management architecture. There are still many more data processing solutions on GCP, we just covered these two that we thought would be the most suitable for this use case.
Use Case: An Example of Data Mesh Implementation in Google Cloud
A fitness company scenario
Suppose you have a fitness company with the following domains: customer data, fitness insights, and financial performance. You can build data pipelines with Dataflow to automate the ingestion of customer and fitness data, transform it into data products that can be used by these domains, and then move it to BigQuery for storage.
In Dataplex, you can create data lakes for each domain (customer data, fitness information, and finances). Then refer to the datasets you’ve forwarded to BigQuery as Dataplex Assets and unify them to create access policies to be applied across the organization with Cloud IAM. Users can explore this data using Data Catalog in BigQuery or Dataplex, and perform complex queries on discovered data to generate new insights to improve financial performance, for example.
Summary
In this age of big data. a data mesh offers a compelling approach to data management. It empowers domain teams to create high-quality data for consumption, fosters collaboration, and ultimately helps enterprises unlock the true value of their data.
Google’s Data Cloud empowers businesses to seamlessly build a data mesh architecture for their data. It provides innovative tools that facilitate decentralized data ownership, treating data as a product, and creating governance policies to be applied across the data mesh. It also allows enterprises to bring together different services to create a self-serve data platform to make this data easily accessible across the organization.